
The Handshake Engineering organization has had an outstanding couple of months, filled with exponential growth and important investments towards developing our new architecture, Handshake Next (HSN). We've been busy iterating our codebase to support the rapid expansion of our team while introducing new technical processes to streamline the onboarding of new team members. In our last Handshake Next blog post, we discussed how we mapped a layered approach to establish bounded contexts that align with the subdomains of the business. However, as we continue to work on the vision for HSN, it’s critical we also consider how to balance autonomy, collaboration, and clear lines of ownership to ensure that our technical boundaries can scale with the team and are not at odds with the needs of the business and our three user types (Students, Employers, and Educational partners).
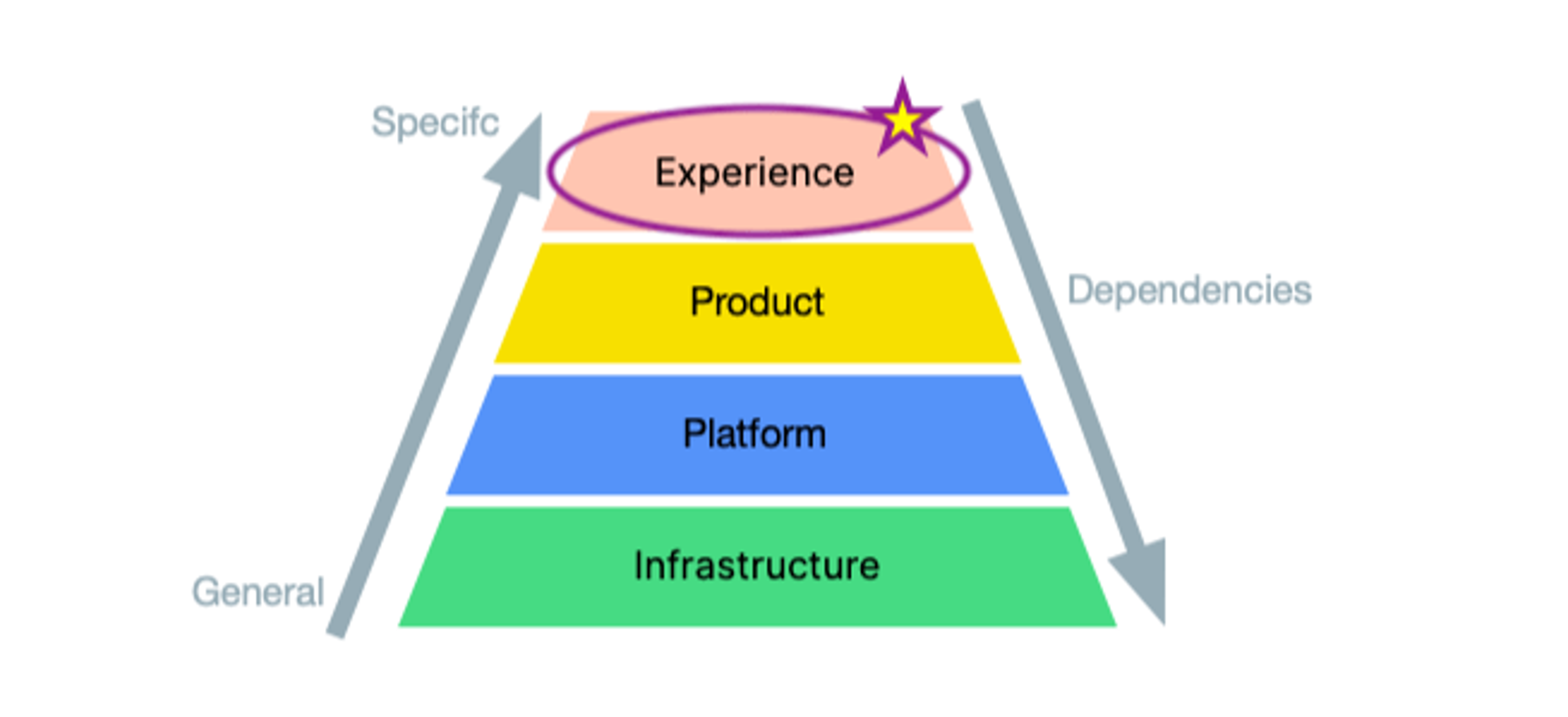
In fact, our engineering organization has been organized by user type for quite some time. So naturally, as we looked at our layered approach from the top down, our first logical boundary to establish for the Experience layer was by user type. In order to establish these bounded contexts, we needed to transition from a monolithic structure to a miniservice structure, with an Experience layer service for each user type. Starting here has a wide range of benefits: it allows teams to take ownership of their miniservices and onboard engineers more efficiently. It also increases the speed of new code development and decreases the chances for unintended side effects that come with a large, complex codebase.
This post will discuss the decisions made and the processes used to undergo the Experience Layer transition. We will cover how we prepared for the transition and the tools we employed to facilitate a smooth transition. Lastly, we will discuss the execution of transitioning the code from the monolith to the miniservices.
BEFORE THE TRANSITION
Before we transitioned the Experience Layer, shared views and endpoints were littered with conditionals based on user type. Here’s an example from the route that returns job postings:
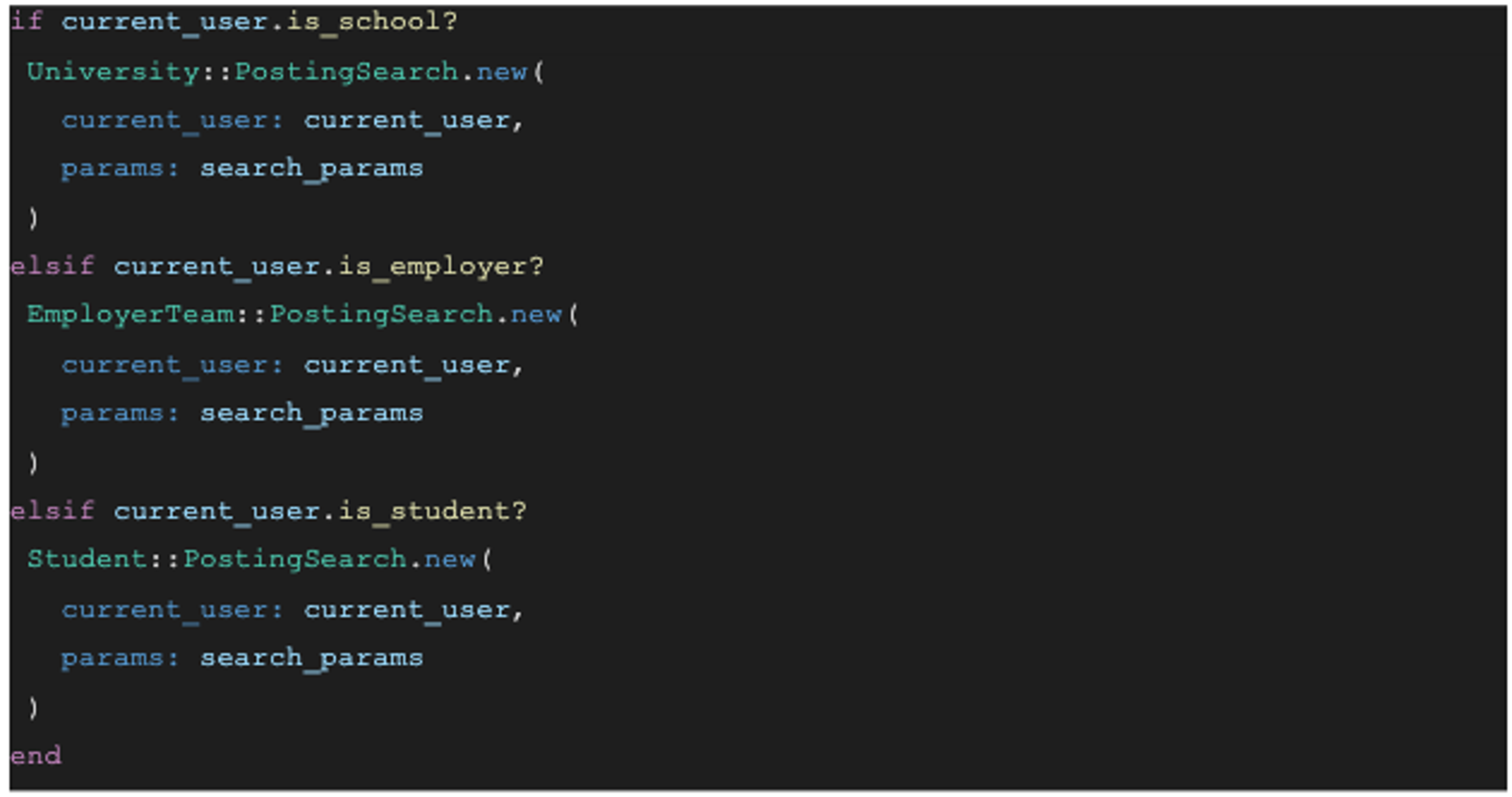
If a bug was discovered for a particular endpoint, some digging had to be done to determine team ownership. The branching logic and conditional behavior were often much less clear than this fairly straightforward example. Engineers would change code without realizing that it impacted other user types. We decided to start our Handshake Next journey to solve this problem. In particular, we decided to create a miniservice for each user type experience based on path prefixes.
Each miniservice is a Rails Engine mounted in our main Rails application. Standard Rails routing combined with Middleware and Routing Constraints ensures that users' requests are sent to the right endpoint in either the main application or in a miniservice controller.
PREPARATION
Before we could begin copying files from the monolith into these new miniservices, a core team of engineers worked on the details for four months. They decided what code should live in the new miniservices, built redirect middleware to ensure that the Handshake application would continue to function seamlessly for end users, and developed automated scripts and documentation for copying code to the new miniservices.
WHAT TO MIGRATE TO THE NEW SERVICES
A critical component of our preparation was determining what to move to the Experience Layer miniservices and how to do so. Many discussions centered around a focal question: if all user types utilize an endpoint, shouldn't we leave it in the monolith? Ultimately, we decided that each endpoint used by a particular user type should be copied to that service. Although the endpoint may be the same for each user type, we intentionally opted for clear service boundaries (for this phase in the transition, DRY code is less useful than the benefits gained by establishing clear ownership and service boundaries).
In the first blog post, we talked about a four-layer architecture- from the top down: experience, product, platform, and infrastructure. So what types of files actually belong in the Experience Layer? Our engineers determined this layer should encompass routing, controller, & UI layers. To start, we included controllers, views, presenters, and helpers in the new miniservices. Instead of going file by file to determine which of these belonged in each miniservice, we went controller by controller. For example, since student users utilize an endpoint to retrieve a job, we copied the jobs controller containing that endpoint and any associated helpers, views, and presenters to the student miniservice.
REDIRECT MIDDLEWARE
Another key capability we needed to create was a redirect middleware so that existing routes could continue to function. Also, if a user inadvertently visits an endpoint for another user type, they are appropriately redirected. We wanted to ensure the transition could be done iteratively, with easy rollback, and avoided a "big bang" switch. The redirect middleware that we built helped guarantee a continuous and seamless user experience, redirecting to the monolith when a particular endpoint is not found in a miniservice (and vice versa) as we progressed through the transition.
The Rack Middleware determines if a request should be redirected to a new miniservice. Additionally, it determines if a request is going to a miniservice that's not ready to service the request, and redirects it back to the legacy route. In order to implement this functionality, we leveraged Rails Routing constraints.
There were some exceptional routes that we chose not to move at this time. For example, we have plans to create a new experience service in the future for authentication-related workflows.
Another issue we encountered involved client-side routing. For example, we use React Router in a few locations, which updates the URL path without making a server call. Additionally, when using React Router, components conditionally render based on the URL path. For these instances, since it is not redirected to the miniservice, we updated the frontend code to prepend the appropriate miniservice prefix.
AUTOMATION & TOOLING
We decided on two phases of execution for the migration in order to ensure our automation was fast and straightforward. Phase 1 copies the existing monolith controllers into each miniservice where needed. Phase 2 cleans up all unrelated code from each miniservice. We rapidly achieved isolation by separating these two steps. Phase 2 can be done on different timelines by different teams without requiring coordination.
During the copy phase, we also needed to manipulate the code being copied. For example, the new code must be properly nested under a module namespace that matches the namespace of the Rails Engine. (In some cases) References to classes and modules need to reference the new version in the Engine rather than the legacy one. The same idea applied to Rails Partial rendering. Almost all of these changes could be fully automated. In some more complex cases, we leveraged rubocop-ast to confidently revise the code.
RUBOCOP-AST REVISIONS
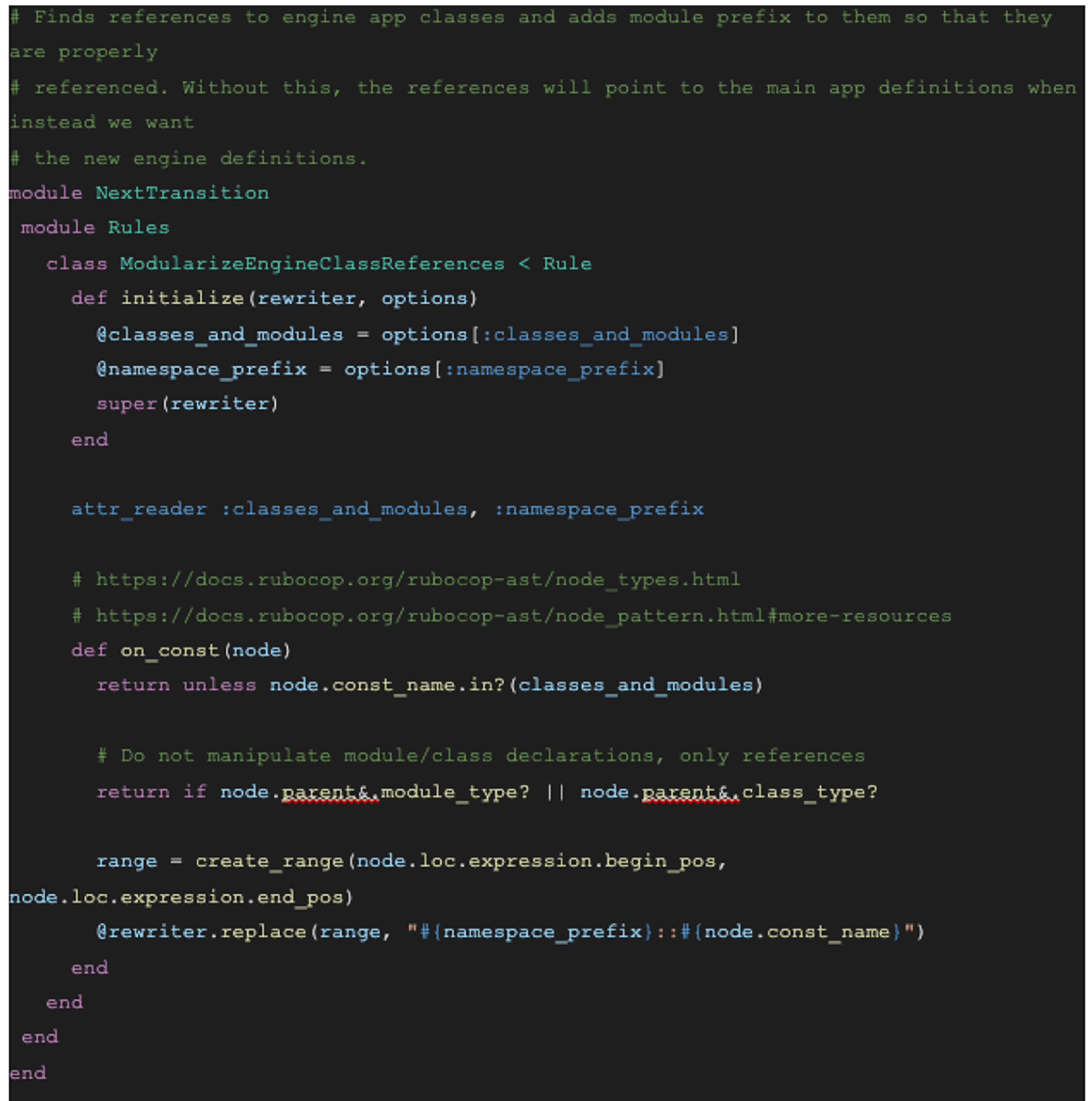
Rubocop-ast leverages Ruby Abstract Syntax Tree, which breaks a program apart into a tree structure with nested nodes. As an example of using rubocop-ast, let’s look at adding the proper namespace to referenced classes. In the code below, we add the module namespace prefix to a class reference if the class being referenced is in the new Engine. For example, PostingSerializer might be changed to Next::Edu::PostingSerializer:
GIT HISTORY
As we copied files from one location in our repository to a new location, we wanted to preserve GIT history for each file in both locations, as it is a useful way to view past Pull Request (PR) descriptions and to learn about files and features. The secret git recipe wound up being a move followed by a checkout of the original file:

Using this approach preserves the “git blame” details for each file. (Note: for this to work, you must also perform a non-squashing merge when merging PRs in Github instead of squashing).
EXECUTION
SWARMING
How does an organization copy thousands of files that engineers are currently developing without coding conflicts? This was one of the many questions we needed to answer to execute the transition. In addition to minimizing code conflicts, we wanted to increase visibility, finish the transition quickly, and avoid disruption to our end users. We chose to swarm; we planned a dedicated sprint for each team to focus on performing the Phase One copies for their miniservice. This ensured that we wouldn't lose work during the copy phase, and the transition would be completed quickly. By taking this approach, engineers didn’t need a lookup table to reference which controllers had been transitioned and could confidently determine whether to modify the controllers in the monolith or in a new miniservice. Before the sprint, controllers were modified in the monolith; after the sprint, they were added and modified in the Experience Layer Miniservices. Additionally, we wanted all of engineering to have an opportunity to contribute to building our next architecture.
Once we decided to swarm, we established a timeline with our three teams: Employer, EDU, and Student, and discussed whether to swarm in tandem or consecutively. We adopted the latter approach to minimize risk and disruption to end-users. We found the consecutive approach beneficial for many reasons; each team uncovered common issues with the process from which subsequent teams learned. For example, each team held a retrospective and documented issues that they encountered. In addition, teams recorded the Pull Requests (PRs) for each controller copy (again, many controllers were copied to multiple Experience Layer Miniservices).
By the time that the last team executed their transition, what they had initially estimated would take four weeks took only one week!
Swarming also had the benefit of exposing all engineers to the new miniservices and HSN.
POST TRANSITION LIFE
Another useful tool we employed after the transition was Github's codeowner feature which verifies that the engineering team is modifying the correct code moving forward. As we continue to work on deprecating and removing the monolith code, we've added transition leaders as codeowners to all of the files in the monolith that are copied to miniservices. This action ensures that if anyone modifies the (old) code moving forward, they must receive approval from a transition leader for that special case.
We also added documentation for our engineers to guide them in this new miniservice ecosystem. These components summed up to a significant architectural change, so proper documentation ensured that everyone could understand how the miniservices work and the correct code to edit. Since this was a large refactor, the project leads worked closely with Support throughout the transition, letting them know when each team was scheduled to transition code to their miniservice, what types of issues to look for, and who to contact in case any related tickets were submitted.
Before the transition, we set up monitoring to track URL usage and redirects. The information we gained from our monitoring now shows us how many endpoints have been transitioned and helps us to determine which monolith endpoints we missed copying if they were not redirecting to an Experience Layer miniservice. These learnings also help us reduce our dependence on the middleware to redirect user requests.
CONCLUSION
Transitioning the Experience layer was the first of many projects that will enable us to increase our speed of innovation. By focusing on these initiatives first, we’re forming reliable building blocks and scalable foundations for our new architecture, Handshake Next. The Experience Layer Transition, and more generally, establishing service boundaries, allows us to determine ownership and scale not only our user base, but also as an engineering organization. We encountered several challenges with the transition, yet we're ecstatic with our result—a surprisingly smooth experience. Now, instead of stumbling through confusing, bloated code, each engineering team can take ownership of their miniservice and add features and improvements to it without worrying about impacting other teams or user types.
In a future HSN post, we'll share how we took a slightly different approach to transition our frontend code to the miniservices and outline the learnings and challenges we discovered along the way.
If innovative, challenging work like this excites you, we invite you to explore open roles at joinhandshake.com/careers. We're building a technical team of savvy engineers and creative problem solvers motivated by meaningful, high-quality, high-impact projects.
Join us as we continue to build Handshake Next.