
A while back, I was sent a design mockup which included a rather inconspicuous change to the user settings page. In place of the single “email address” field, you could now enter multiple emails, and designate one of them as primary. I immediately started raising questions to see if this was a hard requirement, because I knew that it was going to be way more work than anyone outside of engineering probably assumed it would be.
What’s the Big Deal?
This change would need to involve replacing our email_address column on the users table with something that could support multiple values. That, in itself, is pretty straightforward:
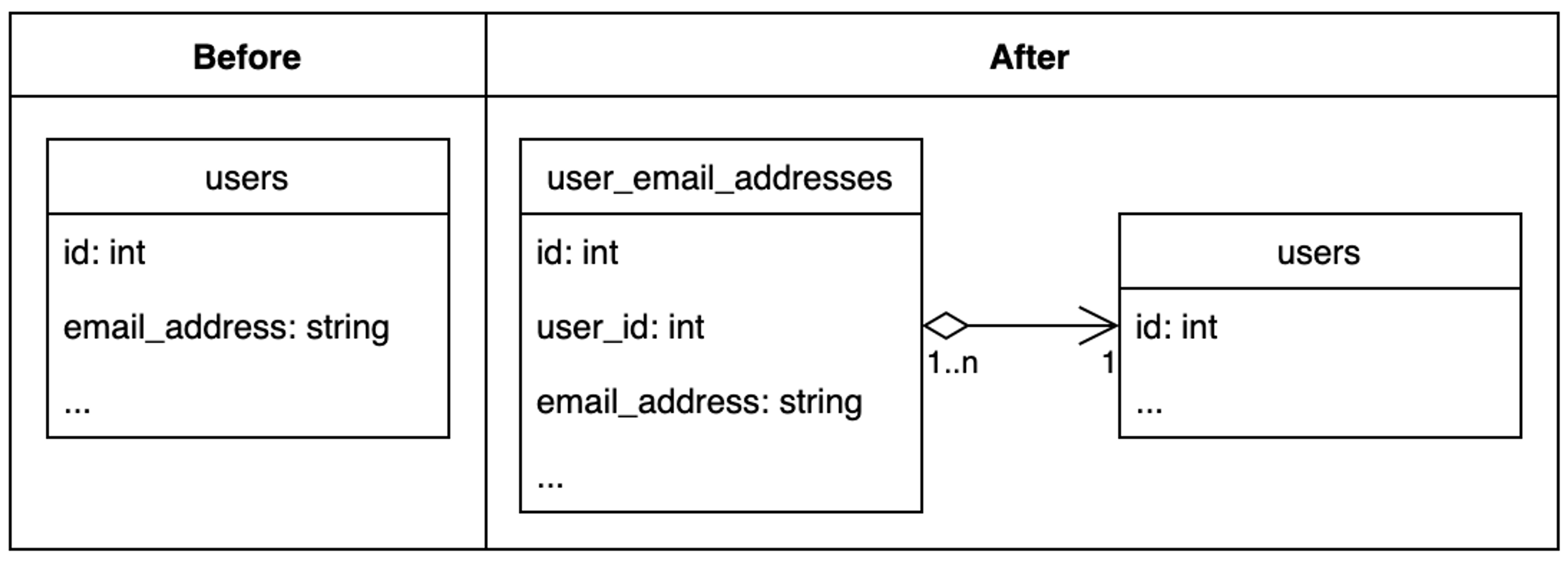
What makes it considerably more complicated is that we need to make this change in a way that doesn’t require any downtime (or freezing of updates to emails, which happen pretty much constantly when you have millions of users), and could be rolled back at any point (in case of mistakes).
Those requirements make it a fairly involved, multi-step process:
- Create the new database structure.
- Set up write forwarding, so that changes to the old structure get copied over to the new one, and vice-versa. This ensures that at any point in the process, we can revert any/all of our changes, and users won’t see any data suddenly change back to a previous value.
- Copy over all values from the old data structure into the new one.
- Update all code which reads this data to read from the new structure.
- Update all code which writes this data to write to the new structure.
- Tear down write forwarding and drop the old data.
- Now you can make whatever user-facing changes you wanted to make.
This is already complex enough that it’s worth double-checking with PM and Design to make sure that this change is important enough to spend a nontrivial amount of time on it. But as long as that’s confirmed, this is a drill we’re familiar with; we’ll make some Jira issues for it and slot it into some upcoming sprints.
But this email thing was so much more than just that. I thought for sure that once people understood what was required, they’d never want to spend that much dev time on what looks like such a small change to user settings.
Some selected reasons that this change was going to be big:
- In Handshake, a user’s email isn’t just a piece of contact info. It’s also the mechanism we use to verify their affiliation with an organization. This makes it much easier to maintain a network which is almost entirely free of scammers and spam bots.
- Students need to use an email that their educational institution tells us belongs to an enrolled student.
- Recruiters need to use their work email, which verifies they work at that company.
- Because the id of a Handshake user doesn’t really mean anything to anyone, emails are used in a bunch of user workflows where you need to look up another user.
- Email is often used to figure out whether a Handshake user is the same person as a user in some external system.
The list could go on in a lot more detail, but I’d summarize most of it as “email is sometimes used as an identifier.” So changes to it have to be managed very carefully, and there’s a ton of complex business logic where it isn’t immediately obvious what the actual requirements and assumptions are regarding emails.
On top of the complex business logic, there are huge logistical challenges:
- If you do a search for email_address across the Handshake codebase, you’ll find literally thousands of references.
- We have multiple other database tables that also have an email_address column. Those don’t need to be changed, but it’s going to be a lot of work to even go through the list and determine which of those email_addresses are actually referring to the column on the users table.
- We use Ruby, and one of that language’s downsides is that it’s difficult to automatically find all references to one specific method, when there are other methods with the same name.1
- It’s not just the thousands of current references to email_address that we’ll have to deal with; there’s also new references being added all the time, by engineers across the whole company.
This all adds up to steps 4 and 5 from the outline above lasting for a very, very long time. When I was asked to put an estimate on that,2 I think my pseudo-scientific guess added up to something like 30 engineer-weeks. After some discussion, the decision was made that this was worth that much investment,3 so we put it on the roadmap. There were some… interruptions... that happened in 2020, so it ended up actually taking about a year.
Making it Happen
In principle, the plan was the same as what I outlined above for any database structure change. But because of the additional considerations for this specific case, we had to be a lot more specific about some of the details up front.
First, one thing that we decided against: we were not going to override the email_address method on the User class, and have it return a value from the new user_email_addresses table. That would have saved a ton of time tediously going over every reference to email_address and updating it to use the new structure, but the problem is that there’s no single answer to which email address should be returned, if a user can now have multiple. If we’re using the email address to actually, well, send an email, we want to use the address that the user has selected as primary. But if it’s one of those use cases where the email is more like an identifier string, we need to use the same email we’ve always used for that user. This is the same reason that we couldn’t just allow users to (more easily) update the value in email_address directly, and avoid the need for any database refactoring at all.
I’m going to describe the details of the plan in terms of this specific change involving email addresses, but I think many of these things can be generalized to large and high-consequence refactors in general. I’ll also use terminology and example code from Rails, but I don’t think there’s anything here that really depends on Rails specifically.
Establish Concepts Early
In order to be more specific about the various things that email_address was being used for, we established two distinct concepts, manifested as methods on the User class. A user’s primary_email is the address at which they wish to receive actual emails, and their institution_managed_email is that “identifier” email that their educational institution or employer uses to identify them as a student / employee. Initially, these would be the same address, just copied over from the old email_address column. But the logic for selecting the correct address was, from the beginning, the final logic that we wanted after all changes had been made.4 This setup means that we only had to update each email_address reference once, and once we actually add the ability for users to add emails and select which one is primary, we don’t need to re-review everything to make sure the correct address is being used for each situation.
Take your Checklist Seriously
Any project of this size needs some sort of checklist, both to make sure you don’t forget anything, and as a way to keep people updated on the project’s progress. Creating and maintaining that checklist was more difficult than usual for this project, due to the sheer number of individual changes that needed to be made, as well as the fact that items were being added to and removed from the list all the time (any time someone added or removed code which referenced the email_address column).
The “real” checklist is ultimately the codebase itself – the amount of work we have left to do is exactly equal to the number of remaining references to the email_address column. But as mentioned previously, not every instance of the string email_address in the codebase is actually something that needs to change, so even reviewing this “checklist” to see what’s still left is quite tedious. It also involves a lot of duplicated work, because you end up re-reviewing each of the hundreds of email_addresses that don’t need to change, every time you want to check what’s left to do.
Any checklist external to the codebase (e.g., Jira issues) has other problems. If you summarize a bunch of references together (by feature, by workflow, or whatever), then it’s likely that a lot of “miscellaneous” references will slip through the cracks. If you make the checklist items very specific (in the extreme case, one Jira issue per reference in code) then the work of creating and maintaining the checklist itself becomes significant overhead. And you still have to do the thing where you re-review the whole codebase periodically, in order to find new references that need to be added to the list.
Ultimately, I settled on a checklist system based on code comments:
- Create a dedicated git branch, so you can add comments all over the codebase without interfering with anything else
- Do a global search for \bemail_address\b and start reviewing every result
- On each line that has been reviewed, add a comment with something unique that other people probably won’t use in unrelated comments or code – I decided on the envelope emoji because this is an email project ✉️
- On each line that doesn’t need to be changed, add something else to denote that – how about a check mark emoji ✔️
- Now, you can find all unreviewed references using a negative lookahead regex search: \bemail_address\b(?!.*✉)
- Similarly, you can find all items on the “todo list” with: \bemail_address\b(?!.*✔️)
- Periodically merge the main branch into the checklist branch, and review all the new references that people added
Make the Correct Logic Easy
In the new email model, it’s pretty straightforward to start from a user and find the correct email address given the situation. What was previously user.email_address would now be something like user.user_email_addresses.find_by(primary: true).email_address. That’s enough to warrant adding a helper method to the User class (user.primary_email is nicer than writing out the whole thing every time), but it’s not absolutely critical; people could get along fine if that was all they needed to figure out. But other use cases are more complex. Like if you have an email address, and you want to find which user is associated with it, there’s more considerations than might be obvious at first glance. Should it matter whether it’s the primary_email or institution_managed_email, or should we match on either one? We’ll need to also add a condition for the user_email_addresses.confirmed column, to ensure that we don’t match on an email which a user hasn’t actually confirmed they have access to. But an annoying, very non-obvious detail is that an institution_managed email may or may not be confirmed (because… legacy code, just don’t worry about it). So the logic that you probably want is:
…and in reality, it quickly gets more complicated than that for many other reasons which are not the focus of this blog post.5 Suffice it to say that in order to write some of the final queries, I had to review the docs on LEFT JOIN LATERAL and other such exotic SQL syntax more than once.
So, given all of that, every time I got a question from someone along the lines of “how do I look up the user_email_address for…”, I responded with “let’s schedule a call so I can understand your use case, and we’ll write a helper method on User for it”. If the correct option isn’t the easiest option (i.e., User.with_email('someone@school.edu')), then we’re going to deal with a steady stream of bugs for the foreseeable future until it is the easiest option.
Commit to the Full Refactor
Closely related to the previous point, the easiest and most obvious option is always going to be writing user.email_address or User.find_by(email_address: email). We could talk with everyone who makes that mistake (after the bug report comes in to let us know that said mistake was made), and tell them to use the situation-appropriate helper method instead, but then we’re just going to repeat that process for every new hire, and clearly that’s not sustainable.
The solution is to make it impossible to use the legacy data structure. That ultimately means that we needed to drop the users.email_address column from the database. Anything short of that would still allow someone to very easily just write user.email_address and introduce a bug.6
Dropping that column is scary. It means that if any mistakes were made in the process leading up to that, and those mistakes were not caught, we have no way of reverting. There are ways (outlined in the next section) to make this less scary than it sounds initially, but it’s still a huge, irreversible action at the end of a process that is otherwise designed to be easily reversible at every step. But after seriously considering all our options, this is a tradeoff I would still recommend making if you’re in a situation similar to ours.
Check Everything at Runtime
No matter how thorough you are with maintaining your checklist, you can only reach a certain level of confidence by just reviewing code.
To be certain that nothing was referencing email_address anymore, we overrode the getter and setter methods for email_address and added some extra logic. In development and test environments, both getter and setter would raise an exception if called from anywhere besides the write-forwarding code. This already surfaced a couple of missed references just by running the full test suite, and it ensured that anyone who typed user.email_address got immediate, unignorable feedback that they should use the new helper methods instead. In staging and production environments, we just logged that a reference had happened but still returned/set the value as normal. Letting that run in production for a few days surfaced another missed reference or two that the test suite had missed.
Those overrides helped a lot, but there are other ways to reference the column that don’t involve calling the getter or setter methods. The most notable of those is just using it in a query like User.where(email_address: email). For this, we used ActiveRecord’s ignored_columns feature. Unfortunately, that throws errors when you try to use the ignored column, rather than just logging it like we did with the getter/setter overrides. So we made the change in staging environments well ahead of when we planned on doing it in production, and just watched for errors that looked related.
I’m happy to report that, thanks to these precautions, when we actually dropped the email_address column it was totally anti-climactic.
Looking Back
This was quite a lot of work. And a lot of it was kinda tedious, to be honest. If I had been able to convince myself that another, easier option was really going to work long-term, I would have been happy to live with something a bit more hacky.
But it was also not nearly as intimidating as it looked at first. Time-consuming, yes, but with proper planning and the resolve to see it through to the end, it’s entirely doable.
Footnotes
1 It might even be technically impossible, due to the potential for metaprogramming and whatnot, to determine this prior to runtime. But it’s been a while since my programming languages course in college, so I’m just going to stick with “difficult”.
2 This was the first time in my career that I felt like maybe I should give an estimate on how much time it would take me to generate an estimate.
3 The main reason this is actually quite important is that students often lose access to their @school.edu email addresses when they graduate, and this change will make it much easier for them to retain access to their Handshake account after graduation. If it were just a matter of being slightly more convenient to change your contact email, I don’t think I would ever have argued this was worth it.
4 The only exception to this was that there was initially fallback logic in place to return email_address in the event that the lookup on user_email_addresses returned null. That fallback was removed eventually, but the rest of the logic remained unchanged.
5 Did I mention that we’re dealing with legacy code? We’re dealing with legacy code. We need to draw a line somewhere for what we’re going to improve, and what we’re going to work around.
6 We could add some overrides to the User class, to make it so that user.email_address will throw an error, but stop short of dropping the actual database column. But there’s still the whole data team and others who read from the database directly using SQL statements, so overriding ActiveRecord methods doesn’t give them any cues at all.