
As an engineer at Handshake, I help connect employers to qualified students -- particularly ones that fall through the cracks of traditional recruiting. To this end, my team has been developing Candidate Hub, a one stop shop for employers to build relationships with students.
A key part of our efforts has been integrating large data sets with different structures into one efficient search. We wanted to combine a large pool of information about student characteristics with information about how students were engaging with specific employers. Implementing this raised some significant scale challenges, which I'll discuss in this article.
The Problem
Characteristics are student attributes, such as their major, school year, and job roles they have expressed interest in. Characteristics are relevant to all employers. We had several pre-existing features that included searches of characteristic information stored in an Elasticsearch index that aggregated data from a Postgres database, our primary source of truth.
Interactions, on the other hand, are events that occur between a student and an employer. Our platform gives students many ways to engage with employers, such as exchanging messages or attending a virtual one-on-one. Unlike characteristics, a given interaction is only relevant to one employer. Information about interactions is stored in multiple different tables in Postgres.
Searching interactions in conjunction with characteristics would give employers a powerful way to find and personalize their communications with the student. But actually implementing this search immediately raised some challenges. In addition to the structural differences, both data sets are large, together representing multiple terabytes. They also both get updated frequently as students use our platform.
Initially, we experimented with an approach where we stored these data sets separately, only joining them at query time. However, this required us to join potentially very large result sets, leading to a massive transfer of data between systems and an unacceptably high query latency.
We also considered precomputing the results, but doing so would prevent our employers from dynamically filtering their results, severely limiting the value of the search.
We concluded that the only way to deliver the experience we wanted was to unify these two data sets into one searchable system. We just had to figure out what kind of system could meet all our requirements.
The Right Tool for the Job
Historically, Handshake has used Elasticsearch to support searches. Elasticsearch is flexible, scales well, and has an excellent community of knowledge and support. We had many Elasticsearch-based searches in production, but none approached the complexity of our current problem.
Typically when building an index, we would denormalize relational data from our Postgres database to achieve the best search performance. We had used this approach to create our characteristics Elasticsearch index, which pulled data from nearly thirty different Postgres tables.
However, interactions and characteristics didn't seem to fit neatly into a single denormalized document. We naturally wanted to model this data as a query-time join, where a student document containing the characteristic information would join to separate documents representing their interactions.
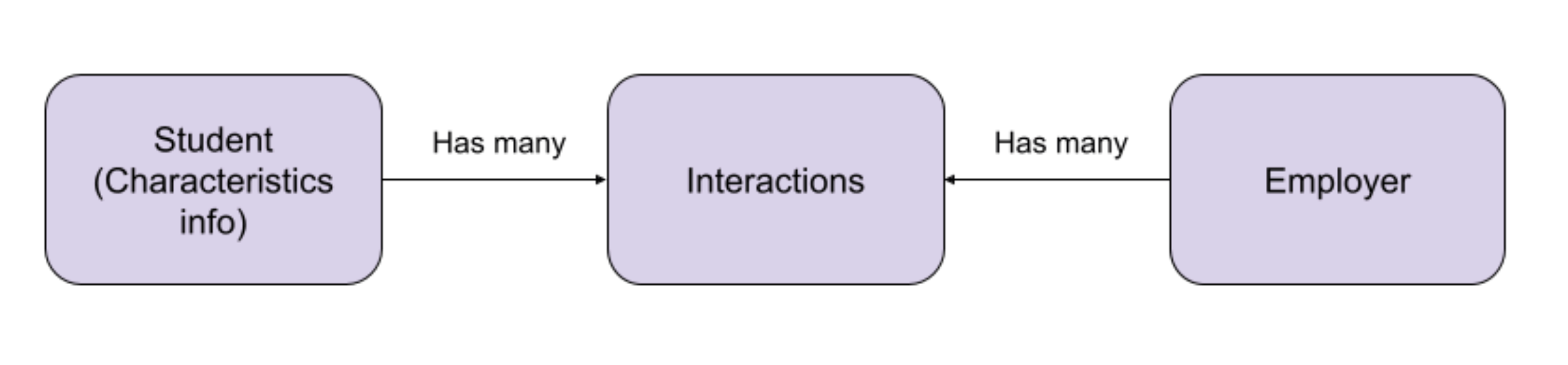
Given this mismatch between our mental model and Elasticsearch, we wondered if there was a better tool out there for our problem. Our ideal system would have:
- Some method of joining across data types
- The ability to search multiple dimensions efficiently, like Elasticsearch's inverted indexes
- Low query latency
- Enterprise grade SLAs
With this criteria in mind, we considered several options to meet our data storage needs, including graph databases, Bigtable, and Apache Druid.
Graph Databases
Graph Databases, such as Neo4J or Amazon Neptune, offer the ability to search data based on its relationships with each other. This was a clear fit for interactions, which are relationships between students and employers. However, we were less clear on how graph databases would support our complex use cases for characteristic searches.
We decided graph databases were too risky to pursue for this project, but we'd like to revisit them when we have a clearer use case!
Bigtable
Google Cloud Platform's Bigtable database (and its more full-featured cousin, Datastore) is an enterprise grade NoSQL key-value store that works particularly well for time-series data. We were initially hopeful that its ability to support potentially thousands of columns in a data set would make it feasible to store interaction data alongside characteristic information. Unfortunately, while it would have been an excellent system for storing raw interaction data, using it for the unified data set would have required a prohibitive amount of duplication of characteristics.
Apache Druid
Apache Druid offers both some benefits of time series databases as well as some fuzzy field searching with a SQL-like query DSL. It supports semi-joins, in which the output from one query is fed into another. Unfortunately, we found the expected results from each of our datasets would exceed the volume we could handle in a semi-join.
Back to Elastic
None of the options we explored fit our use cases well enough to meet our bar for adopting a new technology, and so we turned our attention back to one we already trusted: Elasticsearch. We began exploring efficient ways to store and search our unified data sets. This led us to the world of Elasticsearch joins.
Elasticsearch Joins
Elasticsearch offers two strategies to handle simple joins: nested fields and parent-child joins. The Elasticsearch documentation offers basic explanations for each approach. Based on that information, we thought either could apply to our problem, so we undertook an in-depth comparison of each.
Nested Fields
With the Nested field approach, we would store the unified data for a specific student in a single document. That document would contain the student's characteristics as top level fields, and store the interactions in special nested fields. These nested fields would be structured as arrays of objects representing individual interactions.
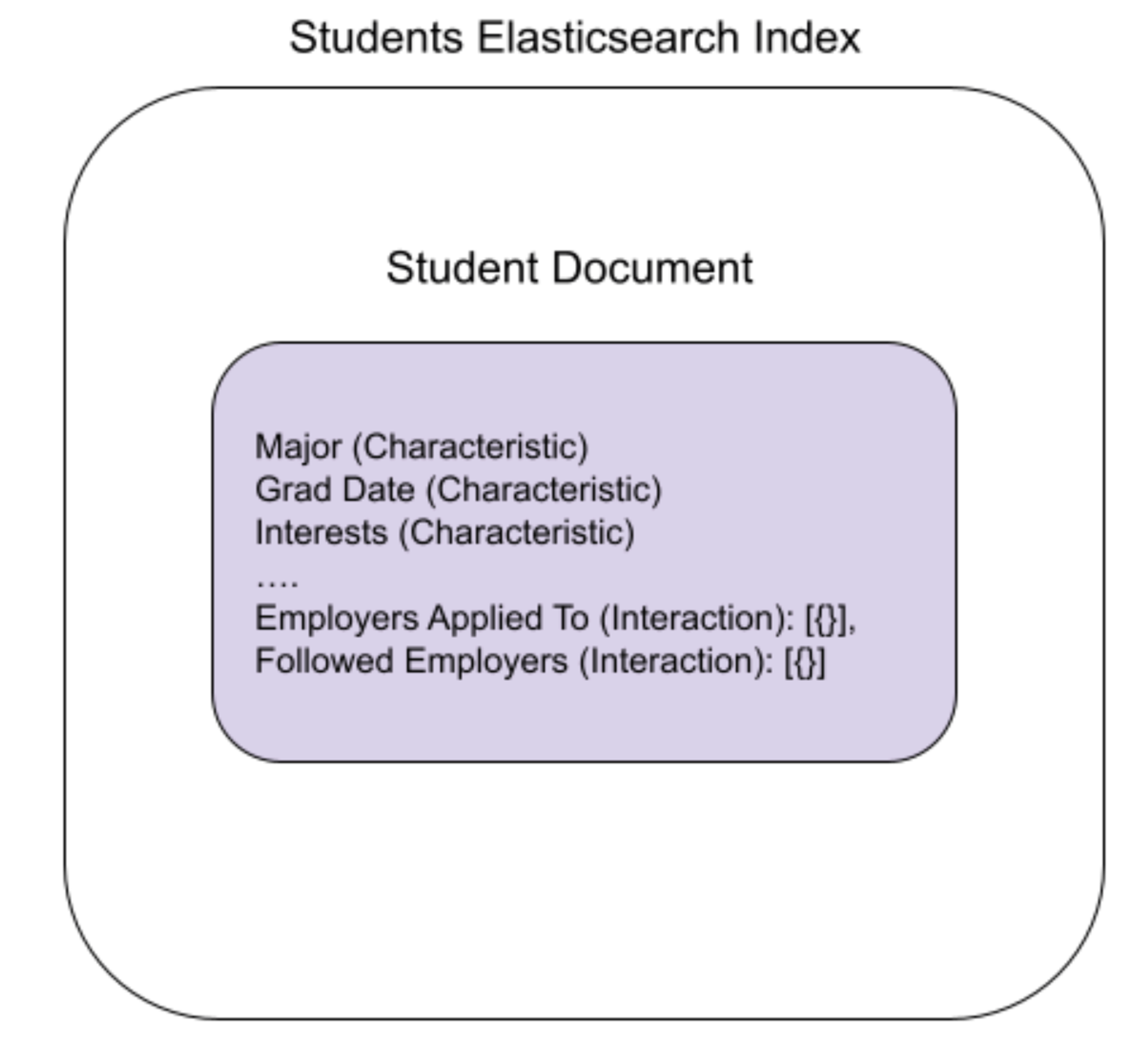
Internally, Elasticsearch will store these nested objects as separate but closely related documents. This is invisible to consumers of the index.
Pros of the Nested Field Approach:
- The efficient format of document storage means queries on nested documents don't suffer a performance penalty.
- This architecture fit our existing patterns of homogenous Elasticsearch indices, in which we expect our indices to contain a single "type" of data, as opposed to a mix of characteristic and interaction data.
Cons of the Nested Field Approach:
- Indexing performance can degrade when there are large amounts of nested documents. Elasticsearch must internally reindex both the parent document and all its nested documents any time any of the nested children are modified.
- Data isolation becomes the responsibility of our business logic, rather than being built into our queries. A single student document contains information about the interactions with multiple employers, so it becomes the responsibility of our code to ensure one employer couldn't access another employer's data.
Parent-Child Joins
With the parent-child join approach, we would have a single Elasticsearch index that contains two kinds of documents: parent documents corresponding to characteristics, and child documents corresponding to interactions. Child documents must be stored on the same shard as the parent document, but otherwise they are completely separate documents. We then would be able to query for parent documents whose children met our search conditions. Intuitively, this seemed like a good fit for our use case.
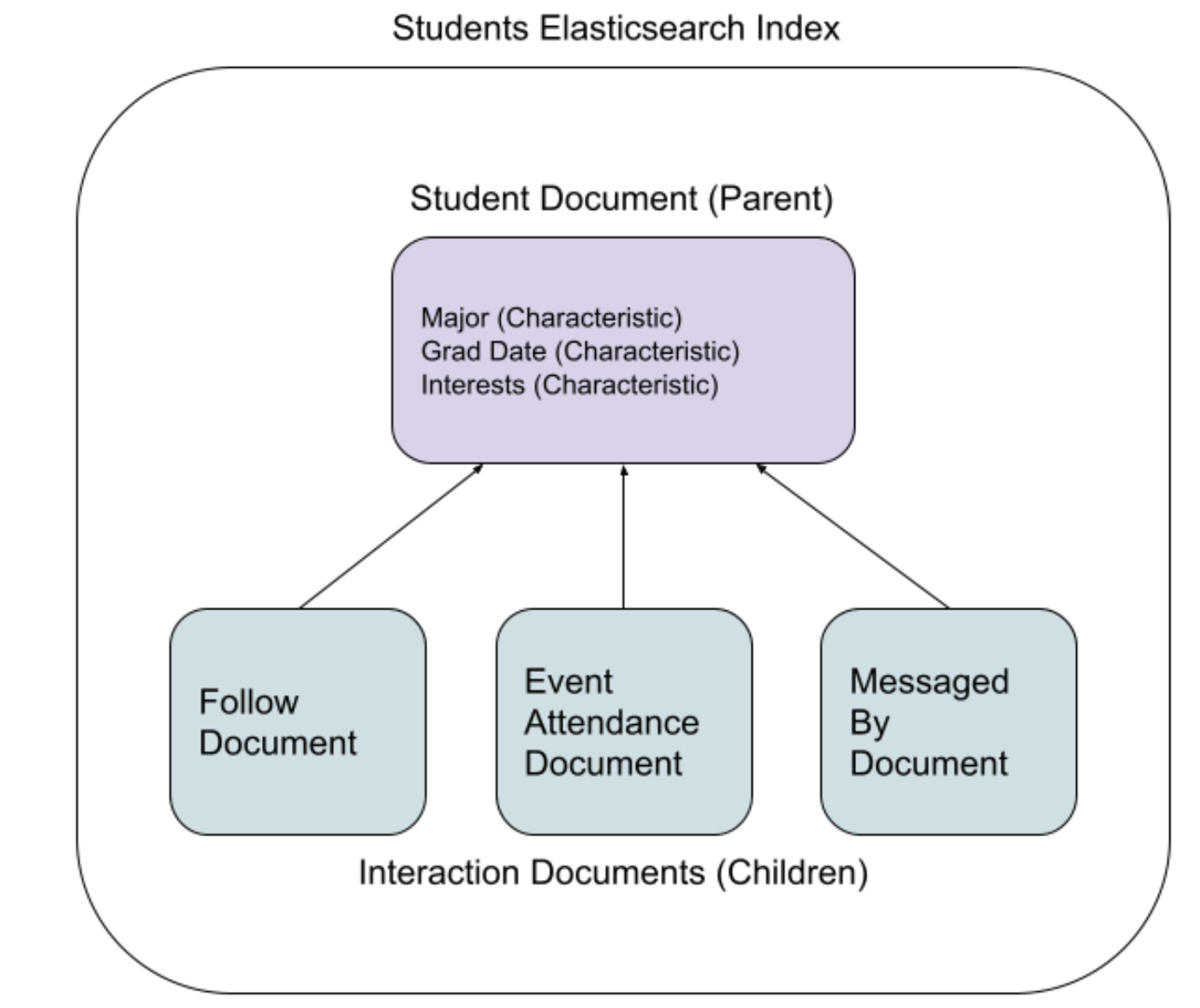
The Elasticsearch documentation, however, informed us that the parent-child joins are discouraged due to the performance hit of joined queries. Unsure of the real world impact, we did performance testing on a simplified workload. Our tests showed no significant difference between nested field queries and parent child joins, but based on our analysis of the difference in storage formats we estimated that parent-child queries would likely be 2-3 times slower on our production dataset.
Pros of the Parent-Child Join Approach:
- Better indexing performance than nested fields, since child documents are totally separate from the parent documents and can be updated independently.
- Better data isolation -- we can scope our queries to only return data from one employer.
Cons of the Parent-Child Approach:
- Expected 2-3x slower query performance than nested fields.
- Added complexity in our indexing pipeline to ensure that child documents end up on the same shard as their parent document.
- Breaks the pattern of our existing Elasticsearch code, which assumes each index only contains one kind of document
The Decision
After evaluating these pros and cons, we decided to pursue the nested pattern for our next version of Candidate Hub!
The major deciding factors were the expected query performance, the lower disruption to our existing architecture, and the lower cost to change -- because of the lower effort to implement, it's less costly for us to switch from nested fields to parent-child joins than the reverse.
This doesn't mean we've ruled out revisiting parent-child joins in the future. This particular data set was not updated frequently enough that the indexing performance was a major concern, but future interaction types could be.
While we can't speak to all use cases, we suspect that nested fields are the better default choice for representing similar data sets in Elasticsearch. It's more straightforward to implement, and gives better query performance. The exception to this is use cases with many frequently updated child documents. In that case, the indexing benefits of parent-child joins become more compelling.
Hopefully our experience proves helpful to you the next time you're trying to break down search problems of your own. Expect to hear more from us in the future about how we're using Elasticsearch at Handshake!
Thanks very much to Daniel Tunkelang for his invaluable contributions to this project and this blog post!
Photo by ThisisEngineering RAEng