
Data is a prerequisite for creating a personalized experience. Machine learning algorithms that can deliver personalization at scale require enough data to predict what a diverse set of users may be interested in. Historically, leveraging this data in career services hasn’t been possible. With every university using a separate, bespoke system, there wasn’t enough data (even at the world’s largest universities) to power effective recommendation algorithms.
Let’s take my story, for example. I went to Michigan Tech, a great university in a very remote part of the United States (it’s actually north of about 80% of the Canadian population). My ambitions were not traditional for a student at Michigan Tech. As a first-year student, I arrived dreaming of working in Silicon Valley — a mere 2900 miles away from Michigan Tech’s snowy campus. Even if Michigan Tech’s career management system at the time was using machine learning, it wouldn’t have worked for me for a few reasons:
- Silicon Valley companies weren’t posting their jobs at Michigan Tech. Even if an algorithm knew what I wanted, it wouldn’t do any good if it had nothing to recommend.
- There were perhaps ten students at Michigan Tech who shared my interests. Of those, maybe three had engaged with our online careers platform. Effective machine learning requires hundreds (ideally, thousands) of data points to capture the nuance of interests. The most our school’s system could have had was a handful.
As a result, the online careers platform available when I was a student was unable to provide a personalized experience for me. This deficit, and Handshake’s work to reimagine the career services systems as a network, is an example of a more significant trend that has been progressing across the digital landscape.

Left: A photo of a road sign outside of Houghton, Michigan as a joke for parents venturing to Houghton for the first time.
Right: A photo of Lake Superior just a few miles from Michigan Tech’s campus.
Web 2.0: From databases to networks
The first generation of web systems (Web 1.0) focused on copying real-world process and digitizing it. The architecture of these systems was not conducive to machine learning as they simply couldn’t provide the data machine learning formulas needed to work. The result is that networks are replacing today’s legacy systems at an incredible rate. Here are a few examples:

By connecting people at a massive scale, networks unlock value for every user involved. This has become so widely accepted that the term "network effect" is now used to describe a system where every existing user on the platform benefits in some way when any other joins.
Network effects in Handshake
Handshake was intentionally built as a network from day one. We connect over 17 million students and alumni, 400,000 employers, and over 900 universities. Every time a university, employer, or student joins the Handshake network, it becomes more valuable for every other user. Let's look at a few examples:
Data is Improving the World.
Despite what you may have seen or heard on the news, data is not inherently bad or scary. When responsibly used, data has the capability to solve some of the hardest problems we face as a society. Here are just a few examples:
- The use of data and machine learning is helping scientists predict the impacts of global warming.
- It’s being used by philanthropies like the Bill and Melinda Gates’ Foundation to eradicate some of the world’s worst diseases.
- Genetic data is helping connect long-lost family members while identifying risk factors decades before symptoms show up.
Data is being used to make us safer, healthier, happier, and more efficient every single day.
Like all things, how a company is incentivized to use data matters a lot. In most cases, this is driven by the company’s business model. So to understand Handshake’s approach to data, I think it’s important to understand our business model.
Handshake’s Model and the Business of Big Data
In 2017, The Economist proclaimed that data had surpassed oil as the most valuable commodity. It’s easy to hear this and imagine companies buying and selling data in the same way they would crude oil. While this imagery helps us visualize an abstract concept, it’s also generally not representative of how data works and promotes misinformation.
It’s worth being clear upfront: Handshake does not, and never will, sell data. This would not only be a major violation of our users’ trust, but it would also be illegal — a violation of our terms of service (the contract we have with our users), contracts we have with our universities, and the federal regulations that protect student data. Selling the data in Handshake would eliminate the need for Handshake, and thus would make for a poor business strategy.
Handshake makes money in two ways:
- Career Management suite of tools (University Revenue)
- Premium services for employers (Employer Revenue)
Universities use Handshake to power their back-office operations. From career fair management to appointment scheduling, Handshake makes managing centers more efficient. You can learn more about that here.
Engineering and development teams are expensive (just look at the software engineering job role above) and university careers services budgets alone couldn’t support these types of services. Historically, legacy platforms have charged for services like posting jobs to multiple universities to supplement the revenue from universities and to try and build a healthy business. This opportunity tax on the flow of positions added no real value to employers but was required for sustainable business.
We offer Handshake to all employers for free and give away more value to employers than any other network. Every company can post positions to as many universities as they’d like for free. Event management, career fair registration, application tracking, sourcing, and much more are all included for every company — free of charge.
For companies with more demanding recruiting needs, Handshake also offers services that are uniquely possible because of the network architecture. These premium services are designed to help employers get a more contextual experience from their data:
- How can I more proactively engage students so I see a higher return on investment (ROI) when I visit a university?
- How is my brand performing among students in a demographic I care about? What ways can I better tell my story across these groups?
- What universities should I be visiting / targeting that maybe I’ve previously overlooked?
- How can I more effectively and intelligently follow up with students who visit my team at a career fair?
- How do I most effectively tell my company’s story and build my brand with students?
The tools we’ve built are uniquely possible as a direct result of the activity on the Handshake platform. Take the School Explorer feature (shown in more depth below), for example.
School Explorer leverages Handshake’s university partnerships to help employers discover universities they may not have thought to recruit at based on the roles they’re looking to fill. Looking to hire software developers in the Midwest? You should be recruiting at Michigan Tech, MSOE, Rose-Hulman, and dozens of other universities you may not have thought about.
Students at universities around the US (and soon the UK) benefit from access to high-quality opportunities that they never would have had before the Handshake network. Tools like School Explorer help amplify that and are uniquely possible because of the relationships we have with students, employers, and universities.
Handshake uses data to improve the experience of all users.
Handshake, and the data that moves through it, unlocks immense value for all three sides of our network. In this section, I’ll explore how.
Career Services
As the heart of the network, colleges and universities use Handshake to power their most sophisticated workflows, to engage with their students, and to manage employer relationships. Today, Handshake supports over 900 colleges and universities in the US and is expanding globally.
Trusted Employers
Historically, fraud has been a major issue for career services teams to deal with. Fraudulent users would create fake vacancies, post them to universities, and prey on unsuspecting students. In the disparate legacy systems, fraudsters could run this playbook at every university without being stopped. Even if one university identified them, they could just move on to the next. It’s a despicable practice that resulted in every service running manual checks on every single employer and posting. Email lists sprang up where universities would try to warn each other of a scam before it spread.
Because Handshake is a network, we leverage an employer’s data across the entire network to predict if they may be a fraudulent company. We surface this to universities to inform their approvals — drastically cutting down on the number of fraudulent employers across the network.
You can learn more about trust and safety on the Handshake Network here.
Better Data and Benchmarking
For decades, universities have united to share best practices and compare notes. When it comes to data, bespoke systems made it hard to compare performance since every university had separate fields and reporting capabilities.
An example dashboard available to universities in Handshake showing peer benchmark data.
Using Handshake’s networked approach, we can show universities data on how they compare to similar universities. This can be used in benchmarking conversations and to track the progress of different initiatives on campus.
More (and More Diverse) Opportunities
Traditionally, universities tried to achieve some degree of relevancy by manually curating jobs. Usually, this involved only approving postings that they thought would be of interest to their student population.
This approach is inherently biased and loses the nuance in what students may be looking for based on their unique situation. By connecting universities to a network, Handshake increases the number of opportunities employers choose to post to that institution by 300% on average (based on our US data). This is important, as having lots of diverse opportunities is prerequisite for the personalization our students find so valuable.
The Future
We continue to invest in new features for universities. This year we’re exploring leveraging the data moving through Handshake to enable actionable insights. These tools will empower you to not just look at the data, but seamlessly take action on it.
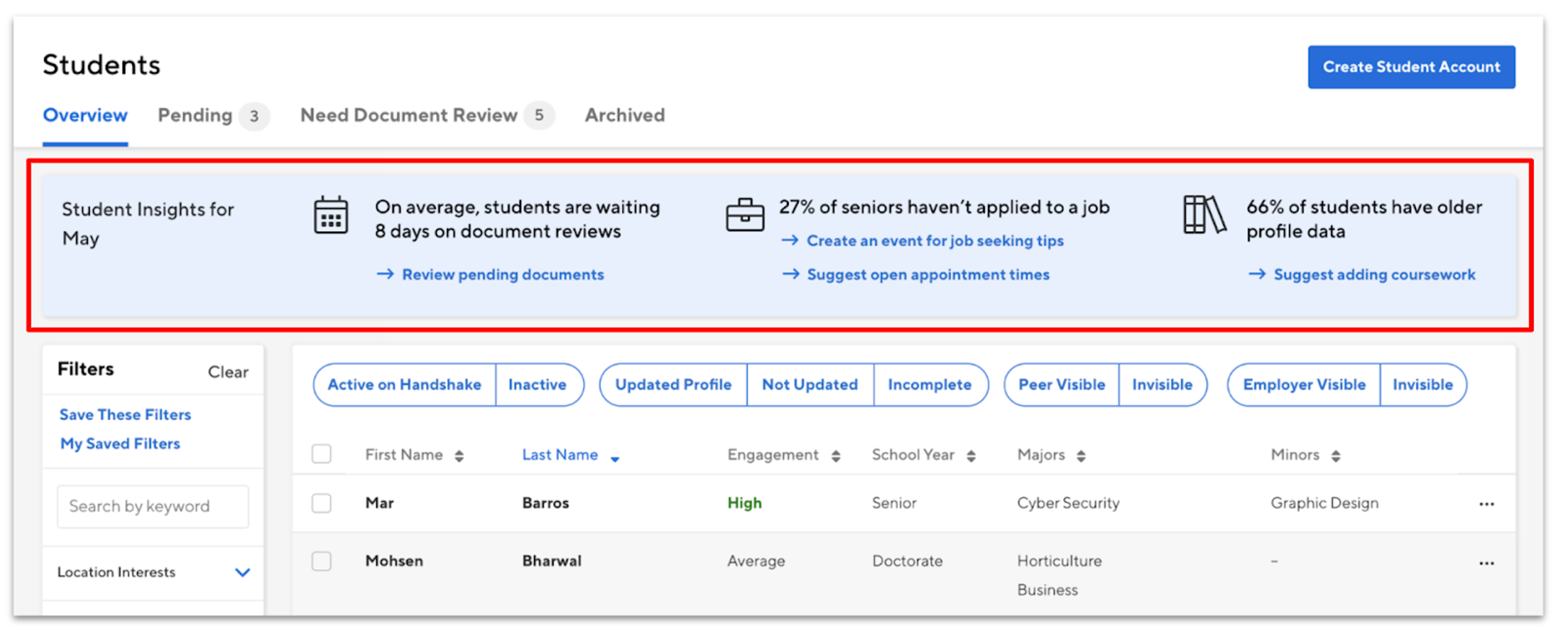
We’re still finalizing what this could look like, but above you’ll see an idea of how this technology could be built into the "Manage Students" page in Handshake to proactively engage students.
Students
Students love Handshake and the data backs that up. The average university sees a 60% increase in student engagement when they switch to Handshake from a legacy provider. There are lots of ways Handshake uses data on the student side, but we’ll focus on one of the reasons students love Handshake — the personalized experience.
Personalization
Data shows that a digital experience is the only touchpoint the majority of students will have with their school’s career services team. Delivering a personalized experience for every student from their first login is of paramount importance. Failing to do so results in misconception about who career services really serve and drives students away. (Cue students saying: “the career center isn’t for students like me.")
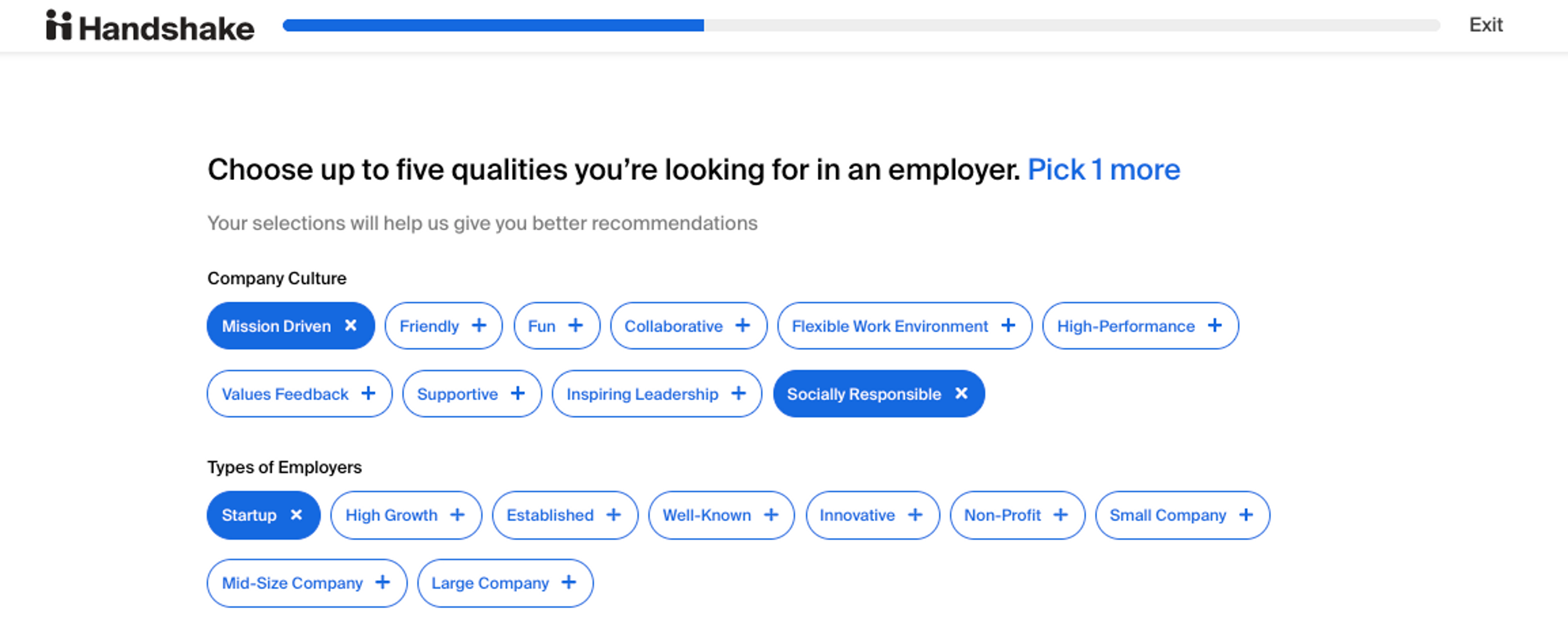
An example of Handshake's student onboarding.
When a student logs into Handshake they go through an on-boarding experience that asks them what they’re looking for. We combine this with the student’s academic data. This data set is then cross-referenced with tens of millions of data points in the Handshake ecosystem to determine what students like them might be interested in. The result? A personalized experience from day one that gets better and better as the student uses it.
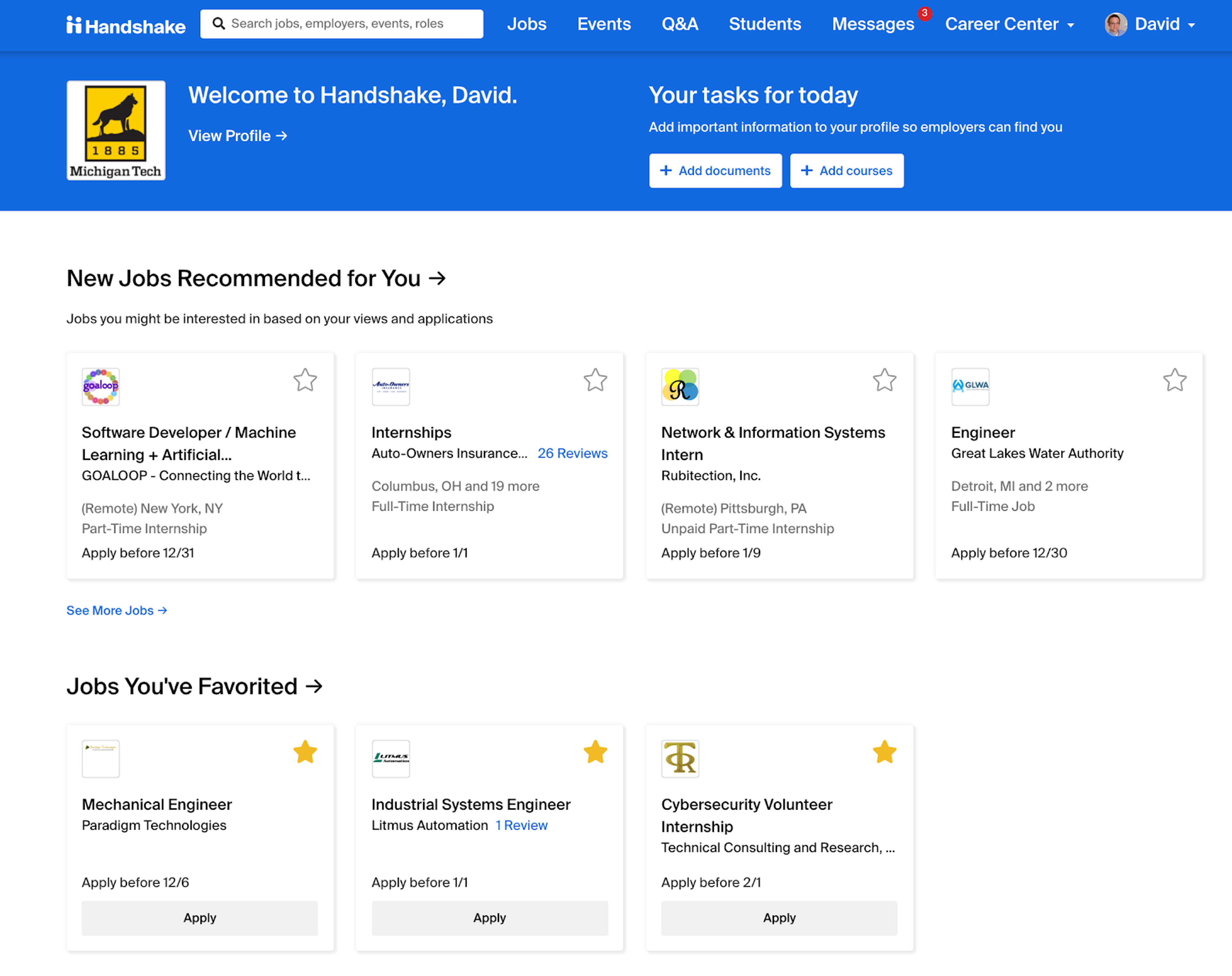
The student dashboard in Handshake featuring personalized recommendations
This relevancy work is a focus of our team of data scientists. Matching student interests with the messy data found in job postings is a difficult task and we’re always working on building a more refined process. For example, our team found dozens of different job titles that all more or less equated to “Software Developer.” Our classification systems are always improving as we get better at predicting the nuances of student interests.
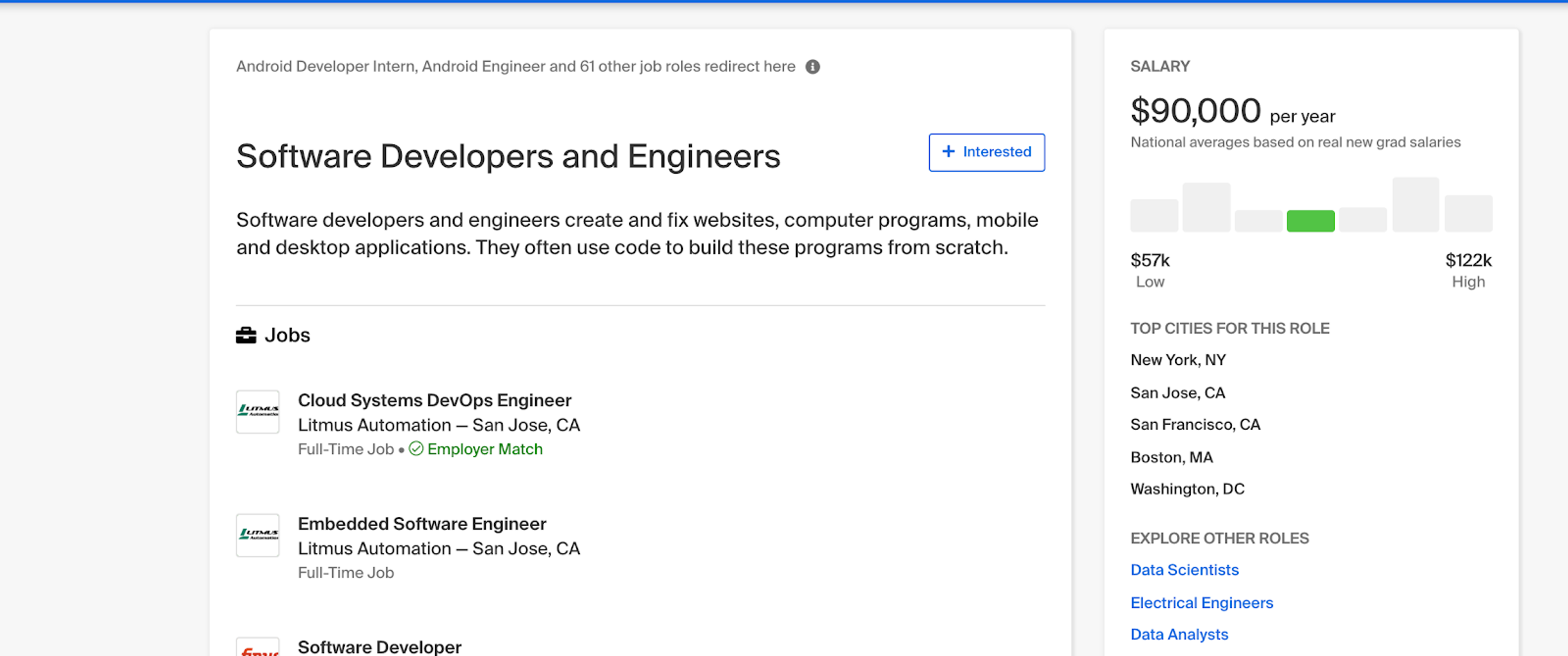
Handshake Job Roles help students discover information about a career path and relevant opportunities, regardless of the job title.
A note on serendipity: some of the most meaningful careers are non-linear and are often unrelated to what a student studies. We get a lot of questions about if our algorithms create echo chambers for students — showing opportunities of the same genre over and over in the name of relevance.
It always surprises career teams to know that we’ve coded for serendipity. Our algorithms are tuned to be about 60% accurate. This means we expect that 60% of what we show a student will be relevant. We then intentionally introduce about 40% of new content to help students discover things they may never have thought to search for and to test our algorithms.
You can read more about our recommendation system here.
Employers
Data adds value to all three sides of the ecosystem. On the employer side, we’ve been piloting a new feature with our premium employer partners that align with our mission as a company — democratizing opportunity.
It’s called the School Explorer, and it uses data to help employers find universities that they may have overlooked, but where data suggest there are many students who would be a great fit for their company. As mentioned above, the data is presenting aggregated and de-identified student groups.
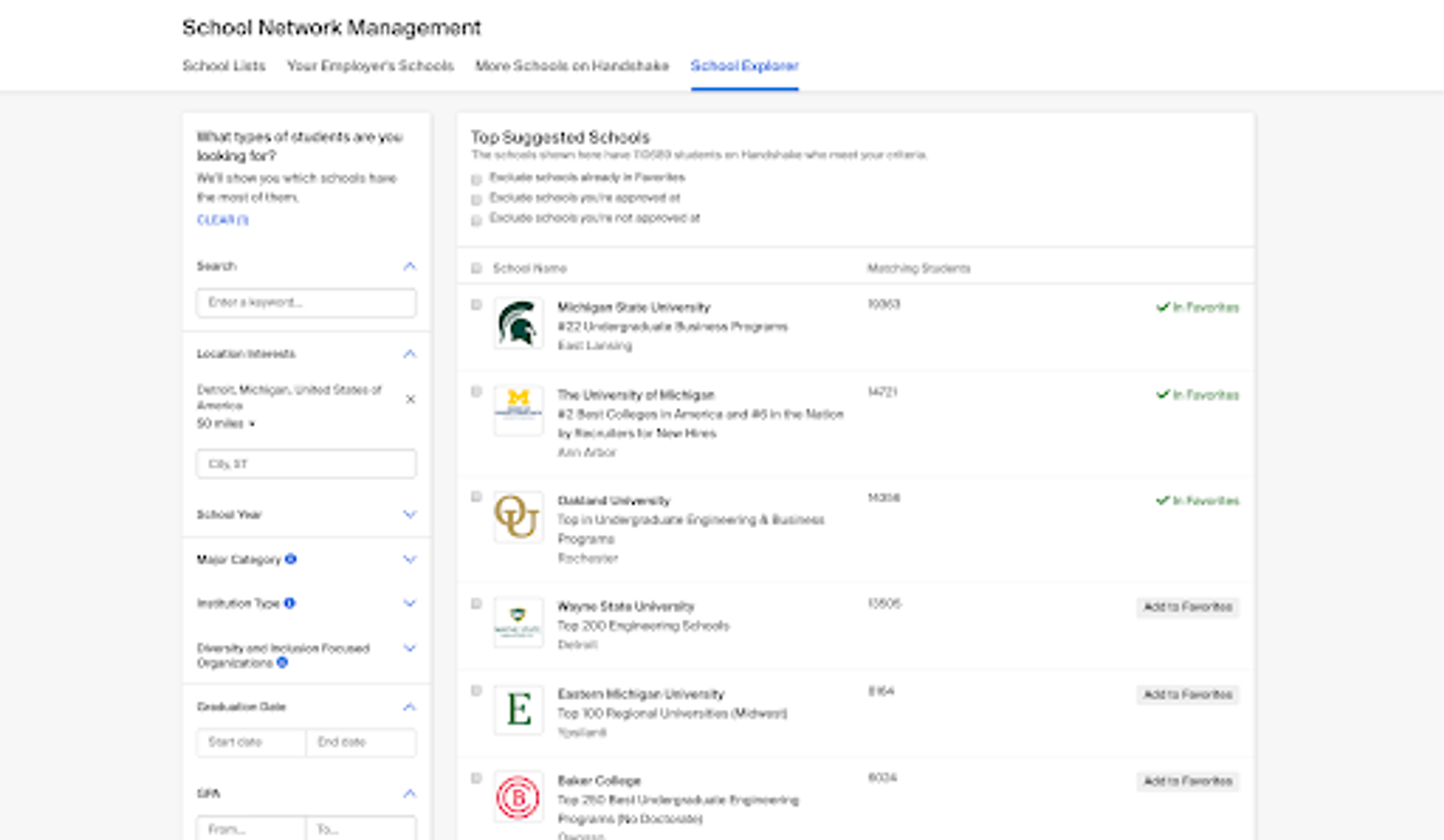
In this example, an employer can easily find universities where a large number of students are interested in working in Detroit.
In this example, an employer can easily find universities where a large number of students are interested in working in Detroit.
This is already having a massive impact on the access to opportunity students have. Take CDW as an example. Historically, CDW has struggled to compete for talent against flashier, consumer facing brands. Since adopting Handshake Premium they’ve rethought their entire university recruitment strategy and increased the number of universities they engage with from 50 to 500.
By leveraging Handshake’s data and our deep relationships with over 900 universities we can help increase opportunity for students around the globe.
Conclusion: Three Questions to Ask When Evaluating Technologies.
As universities seek to engage 100% of their students, the process of evaluating technologies will become more and more crucial. Buzzwords abound — we’ve used a lot of them in this post! We’ll conclude with a framework you can use when evaluating technologies to understand if they’re set up to deliver the level of personalization expected.
What data do you use to train your personalisation algorithms?
- A large data set: Algorithms are only as good as their training data. The smaller and less diverse the data set the less likely it is to be relevant to a diverse population of students.
- You should not have to "seed" the data: If the career service is asked to provide the training data it’s likely you’ll create algorithmic bias. Usually, careers teams only have access to data from students who have used their service, meaning you’re training the algorithm to help the students that are already engaged.
How do you ensure your use of data to protect user privacy?
- User control: Laws like GDPR, FERPA and California’s new privacy law dictate the user must be in full control of how their data is used.
What’s your business model?
- Does their business model incentivize data protection? Do they have defined company values and policies that help inform decisions around data protection?
Data isn’t going away, but it is disrupting entire industries that have been hesitant to embrace the power of networks and data (Taxis → Ridesharing). As universities are asked to do more with fewer resources, systems that can use data to drive efficiencies will become essential.